 Im November 2026 wollte mein Auto mal wieder zum Freundlichen. Besser gesagt, nervte mich der Bordcomputer mit blinkenden Anzeigen und Gepiepe. Nicht wegen vieler gefahrener Kilometer, sondern weil ein Jahr herum war. Als ich in meinen Leihwagen einstieg, ein aktueller VW Polo, fiel mir zuerst das riesige Display auf, das mittig auf dem Armaturenbrett pappte. Mit imposanter Höhe in das Blickfeld durch die Frontscheibe ragte. Den Fahrersitz konnte ich noch einstellen, wie ich es seit meinem Sharan Baujahr 1998 bei VW gewohnt war. Beim Einstellen der Seitenspiegel scheiterte ich. Es gab nicht, wie in meinem Golf VII, einen Knopp in der Armstütze der Tür, wo man die Spiegel verstellen konnte. Stattdessen hätte ich mich auf dem Mäusekino durch Menüs tippen müssen. Ich beschloss, die wenigen Kilometer über Landstraßen nach Hause ohne korrekte Außenspiegel zu fahren. Wenigstens schaffte ich es, dem Radio WDR 5 zu entlocken. Während der Fahrt bombardierte mich das Display hinter dem Lenkrad mit aktueller Geschwindigkeit, Außentemperatur, aktuellen Aktienkursen und momentaner Ausdehnung des Universums. Warum die Geschwindigkeit einmal in Groß und einmal in Klein auf dem Display? Weder Klimaanlage noch Radio-Lautstärke ließen sich über physische Regler einstellen, überall nur Touch. Für mich stand fest, dass mir eine solche Kiste nie ins Haus käme. So etwas Ähnliches hat Gabriel Yoran auch erlebt, doch begonnen hat die ganze Geschichte mit der Bedienung seines AEG-Kochfeldes, das ich auch habe. Das hat 0 – 1 – 3 – 5 – 8 – 10 – 14 – A als Heizstufen. Wer denkt sich so etwas aus? Und kann man darüber ein ganzes Buch schreiben? Man kann, man muss nur den Blick weiten.
Im November 2026 wollte mein Auto mal wieder zum Freundlichen. Besser gesagt, nervte mich der Bordcomputer mit blinkenden Anzeigen und Gepiepe. Nicht wegen vieler gefahrener Kilometer, sondern weil ein Jahr herum war. Als ich in meinen Leihwagen einstieg, ein aktueller VW Polo, fiel mir zuerst das riesige Display auf, das mittig auf dem Armaturenbrett pappte. Mit imposanter Höhe in das Blickfeld durch die Frontscheibe ragte. Den Fahrersitz konnte ich noch einstellen, wie ich es seit meinem Sharan Baujahr 1998 bei VW gewohnt war. Beim Einstellen der Seitenspiegel scheiterte ich. Es gab nicht, wie in meinem Golf VII, einen Knopp in der Armstütze der Tür, wo man die Spiegel verstellen konnte. Stattdessen hätte ich mich auf dem Mäusekino durch Menüs tippen müssen. Ich beschloss, die wenigen Kilometer über Landstraßen nach Hause ohne korrekte Außenspiegel zu fahren. Wenigstens schaffte ich es, dem Radio WDR 5 zu entlocken. Während der Fahrt bombardierte mich das Display hinter dem Lenkrad mit aktueller Geschwindigkeit, Außentemperatur, aktuellen Aktienkursen und momentaner Ausdehnung des Universums. Warum die Geschwindigkeit einmal in Groß und einmal in Klein auf dem Display? Weder Klimaanlage noch Radio-Lautstärke ließen sich über physische Regler einstellen, überall nur Touch. Für mich stand fest, dass mir eine solche Kiste nie ins Haus käme. So etwas Ähnliches hat Gabriel Yoran auch erlebt, doch begonnen hat die ganze Geschichte mit der Bedienung seines AEG-Kochfeldes, das ich auch habe. Das hat 0 – 1 – 3 – 5 – 8 – 10 – 14 – A als Heizstufen. Wer denkt sich so etwas aus? Und kann man darüber ein ganzes Buch schreiben? Man kann, man muss nur den Blick weiten.
Beiträge

 Innerhalb kurzer Zeit hat das Thema "Künstliche Intelligenz", die KI, englisch AI, Jahrzehnte eher schlummerndes Thema in der Informatik, breite Beachtung bekommen. Spätestens mit ChatGPT-40, ein Large Language Model (LLM) von OpenAI, kommt man einer künstlichen Intelligenz scheinbar immer näher. Modelle wie Gemini von Google oder Llama von Meta können, so scheint es, natürliche Fragen verstehen, Antworten generieren und dazu umfangreiche Recherchen durchführen. Neuer Höhepunkt sind Social Bots, auf KI beruhende Mentoren und Berater, die als Partner und mehr dienen sollen. Vor kurzer Zeit las ich, dass eine Frau ihren Social Bot geheiratet hat. Diese Modelle, so scheint es, können Emotionen und Gefühle haben, Empathie leisten und vieles mehr. Aber können Computerprogramme, deren Reaktionen eher auf riesigen Datenmengen aus dem Internet und Wahrscheinlichkeiten beruhen, wirklich Gefühle haben? Das können sie nicht, auch Staubsauger und Airfryer sind nicht zu Emotionen fähig, ein LLM ist auch nur eine Maschine, eine Software. Warum dann der Hype um die Social Bots? Es liegt in der Hauptsache an den Unternehmen, die hinter der künstlichen Intelligenz stehen, und die letzten Endes damit Geld verdienen möchten. So geht Eva Weber-Guskar auch nicht primär auf die Technik dahinter ein, sondern widmet sich philosophischen und psychologischen Aspekten hinter dem "Affective Computing", dem Versuch, der künstlichen Intelligenz Emotionen beizubringen. Wobei Emotionen und Gefühle zwei unterschiedliche Sachen sind, die gerne verwechselt werden. Ganz zu schweigen von den Lügen und Fehlinformationen, die sich Elon Musks KI geleistet hat. Wollen wir das durch Emotionen gesteigert auf die Menschheit loslassen?
Innerhalb kurzer Zeit hat das Thema "Künstliche Intelligenz", die KI, englisch AI, Jahrzehnte eher schlummerndes Thema in der Informatik, breite Beachtung bekommen. Spätestens mit ChatGPT-40, ein Large Language Model (LLM) von OpenAI, kommt man einer künstlichen Intelligenz scheinbar immer näher. Modelle wie Gemini von Google oder Llama von Meta können, so scheint es, natürliche Fragen verstehen, Antworten generieren und dazu umfangreiche Recherchen durchführen. Neuer Höhepunkt sind Social Bots, auf KI beruhende Mentoren und Berater, die als Partner und mehr dienen sollen. Vor kurzer Zeit las ich, dass eine Frau ihren Social Bot geheiratet hat. Diese Modelle, so scheint es, können Emotionen und Gefühle haben, Empathie leisten und vieles mehr. Aber können Computerprogramme, deren Reaktionen eher auf riesigen Datenmengen aus dem Internet und Wahrscheinlichkeiten beruhen, wirklich Gefühle haben? Das können sie nicht, auch Staubsauger und Airfryer sind nicht zu Emotionen fähig, ein LLM ist auch nur eine Maschine, eine Software. Warum dann der Hype um die Social Bots? Es liegt in der Hauptsache an den Unternehmen, die hinter der künstlichen Intelligenz stehen, und die letzten Endes damit Geld verdienen möchten. So geht Eva Weber-Guskar auch nicht primär auf die Technik dahinter ein, sondern widmet sich philosophischen und psychologischen Aspekten hinter dem "Affective Computing", dem Versuch, der künstlichen Intelligenz Emotionen beizubringen. Wobei Emotionen und Gefühle zwei unterschiedliche Sachen sind, die gerne verwechselt werden. Ganz zu schweigen von den Lügen und Fehlinformationen, die sich Elon Musks KI geleistet hat. Wollen wir das durch Emotionen gesteigert auf die Menschheit loslassen?
 Ab 1976 habe ich in Dortmund Informatik studiert, war mehrere Jahre lang Software-Entwickler, bevor ich erst ins Marketing, später in die PR und die schreibende Zunft wechselte. Daher weiß ich, wie Viren, Würmer und Trojaner funktionieren, wie sie Systeme befallen und was dann passiert. Denn irgendwie gehört ein Teil meines Herzens immer noch der IT. In diesem Buch geht es aber nicht primär um technische Details, obwohl die dann doch zur Sprache kommen. Man muss zum Lesen des Buches keine Informatik studiert haben. Eva Wolfangel gilt als Technikjournalistin, die Hintergründe und Wirkungen der digitalen Welt ohne Abtauchen in Spezialwissen behandelt. Es geht nämlich nicht um informationstechnische Einzelheiten, sondern was sich hinter Begriffen wie Cyberwar und hybrider Kriegsführung verbirgt. Und genau an dieser Stelle muss ich zugeben, dass da bei mir eine größere Lücke bestand. Zwar hören oder lesen wir immer wieder Nachrichten, die Russen hätten mal wieder die Technik ukrainischer Kraftwerke gestört, oder dass Nordkorea in die Systeme amerikanischer Rechenzentren eingedrungen sei. Das ist aber nur die ganz dünne Oberfläche, was da hinter den Kulissen wirklich passiert. Wenn zum Beispiel eine russische Schadsoftware einen der größten Logistikbetriebe der Welt für Wochen lahm legt, und keiner mehr weiß, wo welche der 14.000 Container sind und was darin ist. Da kommt Krimistimmung auf.
Ab 1976 habe ich in Dortmund Informatik studiert, war mehrere Jahre lang Software-Entwickler, bevor ich erst ins Marketing, später in die PR und die schreibende Zunft wechselte. Daher weiß ich, wie Viren, Würmer und Trojaner funktionieren, wie sie Systeme befallen und was dann passiert. Denn irgendwie gehört ein Teil meines Herzens immer noch der IT. In diesem Buch geht es aber nicht primär um technische Details, obwohl die dann doch zur Sprache kommen. Man muss zum Lesen des Buches keine Informatik studiert haben. Eva Wolfangel gilt als Technikjournalistin, die Hintergründe und Wirkungen der digitalen Welt ohne Abtauchen in Spezialwissen behandelt. Es geht nämlich nicht um informationstechnische Einzelheiten, sondern was sich hinter Begriffen wie Cyberwar und hybrider Kriegsführung verbirgt. Und genau an dieser Stelle muss ich zugeben, dass da bei mir eine größere Lücke bestand. Zwar hören oder lesen wir immer wieder Nachrichten, die Russen hätten mal wieder die Technik ukrainischer Kraftwerke gestört, oder dass Nordkorea in die Systeme amerikanischer Rechenzentren eingedrungen sei. Das ist aber nur die ganz dünne Oberfläche, was da hinter den Kulissen wirklich passiert. Wenn zum Beispiel eine russische Schadsoftware einen der größten Logistikbetriebe der Welt für Wochen lahm legt, und keiner mehr weiß, wo welche der 14.000 Container sind und was darin ist. Da kommt Krimistimmung auf.
 Philipp Staabs Biografie täuscht nicht. Aus ganzem Herzen Soziologe mit den Schwerpunkten Digitalisierung und Ökonomie, so geriet auch dieses Buch. Lockerer formuliert: ein Brecher, den man nicht mal so eben weg liest. Nun ist Ökonomie nicht unbedingt mein Interessenschwerpunkt, das Digitale und seine Auswirkungen auf Gesellschaft und Politik schon. Bald nach den ersten Seiten wurde mir klar, dass ich mit Staabs Buch keine nette Lektüre für die Mittagsruhe erwischt hatte, sondern ein in viele Details und Tiefen herab steigendes Werk. So schwer sich das Buch liest, so interessant ist Staabs Analyse dessen, was mit dem schwammigen Begriff digitaler Kapitalismus umschrieben wird. Der Verdacht ist berechtigt, es geht um die großen Internet-Herrscher Amazon, Google, Apple, Facebook. Und Konsorten wie Alibaba und WeChat dazu, ihre östlichen Pendants. Nun kann man sich einen schlanken Fuß machen und Amazon nur als eine andere Ausprägung eines Händlers sehen. Ohne weitere Feinheiten wie im Mittelalter die Fugger, heute Otto-Versand oder meine Hundeleckerli-Versorger Bosch und Vitakraft. Doch dieses Sicht ist nicht nur zu kurz, sie ist falsch. Denn es geht bei diesem Thema nicht allein um den Handel, es geht um die Digitalisierung, die Macht der Algorithmen, über die Methoden und Vorgehensweisen, die diese großen Metaplattformen nutzen, um eine ganz neue Art von Kapitalismus aufzuziehen. Als wenn das nicht schon komplex genug wäre, nimmt einen Staab noch mit in eine historische Analyse des Kapitalismus und warum es geradezu zwangsläufig in diese neue Art des Kapitalismus gehen musste. So dass man bei der nächsten Stehparty galant über den Fordismus und den Postfordimus mansplainen kann.
Philipp Staabs Biografie täuscht nicht. Aus ganzem Herzen Soziologe mit den Schwerpunkten Digitalisierung und Ökonomie, so geriet auch dieses Buch. Lockerer formuliert: ein Brecher, den man nicht mal so eben weg liest. Nun ist Ökonomie nicht unbedingt mein Interessenschwerpunkt, das Digitale und seine Auswirkungen auf Gesellschaft und Politik schon. Bald nach den ersten Seiten wurde mir klar, dass ich mit Staabs Buch keine nette Lektüre für die Mittagsruhe erwischt hatte, sondern ein in viele Details und Tiefen herab steigendes Werk. So schwer sich das Buch liest, so interessant ist Staabs Analyse dessen, was mit dem schwammigen Begriff digitaler Kapitalismus umschrieben wird. Der Verdacht ist berechtigt, es geht um die großen Internet-Herrscher Amazon, Google, Apple, Facebook. Und Konsorten wie Alibaba und WeChat dazu, ihre östlichen Pendants. Nun kann man sich einen schlanken Fuß machen und Amazon nur als eine andere Ausprägung eines Händlers sehen. Ohne weitere Feinheiten wie im Mittelalter die Fugger, heute Otto-Versand oder meine Hundeleckerli-Versorger Bosch und Vitakraft. Doch dieses Sicht ist nicht nur zu kurz, sie ist falsch. Denn es geht bei diesem Thema nicht allein um den Handel, es geht um die Digitalisierung, die Macht der Algorithmen, über die Methoden und Vorgehensweisen, die diese großen Metaplattformen nutzen, um eine ganz neue Art von Kapitalismus aufzuziehen. Als wenn das nicht schon komplex genug wäre, nimmt einen Staab noch mit in eine historische Analyse des Kapitalismus und warum es geradezu zwangsläufig in diese neue Art des Kapitalismus gehen musste. So dass man bei der nächsten Stehparty galant über den Fordismus und den Postfordimus mansplainen kann.
 Als das Internet sich Anfang der 1980er verbreitete, war es ein Medium der Wissenschaftler und Ingenieure. Der Zugang war beinahe elitär und mühsam. Mitte der 1990er, mit dem World Wide Web, nutzten es zunehmend auch Privatleute, besonders Musiker, Journalisten, Verlage und erste Online-Händler. Kommerziell wurde das WWW erst mit dem Jahrtausendwechsel. Bestand das WWW dort noch aus Abertausenden kleiner und gleichberechtigter Server, wird das Internet im 21. Jahrhundert vor allen Dingen von den großen Plattformen beherrscht, Facebook und Google, Amazon und Instagram, Microsoft und Apple. Der Begriff der Plattform in diesem Sinne ist relativ jung, doch Plattformen im technischen Sinne gibt es schon lange. Technologisch war es zum Beispiel das System /360 von IBM. Zum ersten Mal versprach der Hersteller, dass alle ab jetzt investierte Software und Hardware praktisch unbegrenzt über die weitere Entwicklung hinaus genutzt werden konnte. Andere Plattformen kamen auf, obwohl sie noch nicht so genannt wurden. Der Apple II, der IBM-PC, später Smartphones mit Android und iOS. Was diese Plattformen sind, wie sie ihre Macht in Netz, Gesellschaft, Kultur und Politik gewannen, wie sie funktionieren und warum, stellt Michael Seemann in diesem nicht gerade schmalen Buch vor. Er beginnt mit der aus seiner Sicht ersten disruptiven Netzanwendung: Napster. Napster stellte nicht nur technisch eine Neuerung dar, sondern forderte zum ersten Mal Wirtschaft und Politik heraus. Der MP3-Tauschdienst ging unter, doch er hatte eine riesige Welle ausgelöst, die nicht nur das Netz, sondern auch unser Verständnis von Gesellschaft und Wirtschaft grundlegend verändert hat. Ohne dass wir es so richtig mitbekommen haben.
Als das Internet sich Anfang der 1980er verbreitete, war es ein Medium der Wissenschaftler und Ingenieure. Der Zugang war beinahe elitär und mühsam. Mitte der 1990er, mit dem World Wide Web, nutzten es zunehmend auch Privatleute, besonders Musiker, Journalisten, Verlage und erste Online-Händler. Kommerziell wurde das WWW erst mit dem Jahrtausendwechsel. Bestand das WWW dort noch aus Abertausenden kleiner und gleichberechtigter Server, wird das Internet im 21. Jahrhundert vor allen Dingen von den großen Plattformen beherrscht, Facebook und Google, Amazon und Instagram, Microsoft und Apple. Der Begriff der Plattform in diesem Sinne ist relativ jung, doch Plattformen im technischen Sinne gibt es schon lange. Technologisch war es zum Beispiel das System /360 von IBM. Zum ersten Mal versprach der Hersteller, dass alle ab jetzt investierte Software und Hardware praktisch unbegrenzt über die weitere Entwicklung hinaus genutzt werden konnte. Andere Plattformen kamen auf, obwohl sie noch nicht so genannt wurden. Der Apple II, der IBM-PC, später Smartphones mit Android und iOS. Was diese Plattformen sind, wie sie ihre Macht in Netz, Gesellschaft, Kultur und Politik gewannen, wie sie funktionieren und warum, stellt Michael Seemann in diesem nicht gerade schmalen Buch vor. Er beginnt mit der aus seiner Sicht ersten disruptiven Netzanwendung: Napster. Napster stellte nicht nur technisch eine Neuerung dar, sondern forderte zum ersten Mal Wirtschaft und Politik heraus. Der MP3-Tauschdienst ging unter, doch er hatte eine riesige Welle ausgelöst, die nicht nur das Netz, sondern auch unser Verständnis von Gesellschaft und Wirtschaft grundlegend verändert hat. Ohne dass wir es so richtig mitbekommen haben.
 Die Max Planck-Gesellschaft gibt alle drei Monate ein Magazin über aktuelle Forschungen an ihren Instituten und über allgemeine Themen der Forschung und Technik heraus. In der aktuellen Ausgabe 01/2022 geht es um die Zukunft von Öl und Gas, über die Wirkung von Stress auf den menschlichen Körper, wie unsere Knochen aufgebaut sind und was sie so belastbar macht, und viele weitere Themen. Die Beiträge sind zwar wissenschaftlich fundiert, trotzdem leicht verständlich und unterhaltsam. Für alle an Wissenschaft und Forschung Interessierten eine empfehlenswerte Lektüre, zudem kostenlos als Printausgabe oder PDF. Erhältlich unter
Die Max Planck-Gesellschaft gibt alle drei Monate ein Magazin über aktuelle Forschungen an ihren Instituten und über allgemeine Themen der Forschung und Technik heraus. In der aktuellen Ausgabe 01/2022 geht es um die Zukunft von Öl und Gas, über die Wirkung von Stress auf den menschlichen Körper, wie unsere Knochen aufgebaut sind und was sie so belastbar macht, und viele weitere Themen. Die Beiträge sind zwar wissenschaftlich fundiert, trotzdem leicht verständlich und unterhaltsam. Für alle an Wissenschaft und Forschung Interessierten eine empfehlenswerte Lektüre, zudem kostenlos als Printausgabe oder PDF. Erhältlich unter
https://www.mpg.de/maxplanckforschung
 Mal keine Philosophie, keine Politik, nicht einmal Soziologie. Ein dickes, schweres Buch über Klänge, Geräusche, Lärm und Musik. Von der Entwicklung der akustischen Umgebung in den Städten während der industriellen Entwicklung, über die Anfänge der Tonaufzeichnung, die Elektrifizierung des Klangs bis in die Gegenwart mit ihrer Kakophonie aus Klingeltönen und die Klangwelten des digitalen Zeitalters. Gegliedert in sechs Kapitel, beginnend 1889 eben bis heute. Es geht nicht nur um Musik, sondern um das Hören und Wahrnehmen, Sound in der Politik und wie sie sich in den verschiedenen Gesellschaftsformen darstellt. Es geht um Grammophon, um Radio, um Propaganda, um alles, was mit unserer akustischen Welt zusammenhängt. Am Rande dann auch um Musik, um Filmmusik, Punk, patriotischen Rock und ein bisschen darum, wie Klänge, besser Sounds, sogar politische Veränderungen begleitet haben. Von der Musik als Funktion und als Emotion.
Mal keine Philosophie, keine Politik, nicht einmal Soziologie. Ein dickes, schweres Buch über Klänge, Geräusche, Lärm und Musik. Von der Entwicklung der akustischen Umgebung in den Städten während der industriellen Entwicklung, über die Anfänge der Tonaufzeichnung, die Elektrifizierung des Klangs bis in die Gegenwart mit ihrer Kakophonie aus Klingeltönen und die Klangwelten des digitalen Zeitalters. Gegliedert in sechs Kapitel, beginnend 1889 eben bis heute. Es geht nicht nur um Musik, sondern um das Hören und Wahrnehmen, Sound in der Politik und wie sie sich in den verschiedenen Gesellschaftsformen darstellt. Es geht um Grammophon, um Radio, um Propaganda, um alles, was mit unserer akustischen Welt zusammenhängt. Am Rande dann auch um Musik, um Filmmusik, Punk, patriotischen Rock und ein bisschen darum, wie Klänge, besser Sounds, sogar politische Veränderungen begleitet haben. Von der Musik als Funktion und als Emotion.
Begleitet werden die 100 Beiträge unterschiedlichster Autoren vieler Wissensbereiche von einer DVD mit mehr als 80 akustischen Dokumenten, die von historischen Klängen bis zu politischen Reden und einfach Geräuschen die Texte ergänzen. Ein Brecher von Buch mit vielen Bildern und Illustrationen. Für ein Buch dieses Umfangs und dieser Tiefe zu einem unfassbar fairen Preis bei der Bundeszentrale für politische Bildung (www.bpb.de). Für alle an der Akustik technisch, kulturell und historisch Interessierten eine tolle Lektüre, die einen lange beschäftigt.
Der Klappentext:
Geräusche, Töne, Stimmen 1889 bis heute
Wie klingt eigentlich Geschichte? Das zwanzigste Jahrhundert erlebte akustische Zäsuren wie keine Zeit zuvor. Was war der charakteristische Sound der politischen und gesellschaftlichen Umwälzungen? Welche Kraft hatten bestimmte Schallereignisse? Wie ist das Verhältnis von Sound und Macht? Wie sehr präg(t)en akustische Welt und Hörsinn den menschlichen Alltag und das historische Geschehen? Schriftliche und bildliche Quellen werden schon lange untersucht, aber in diesem Dossier stehen Geräusche, Töne und Stimmen im Fokus. Die interdisziplinär ausgelegten Beiträge erhellen die sozialen, kulturellen, politischen, wirtschaftlichen oder geschlechterspezifischen Aspekte einzelner Klanggeschichten.
Nein, ich bin nicht arm. Nicht wirklich. Aber ich habe in meiner neuen Wohnung das Problem, dass die Wohnung sehr groß ist. Also ein Luxusproblem. Mein Arbeitszimmer ist ein Schlauch, der nur mit großem Aufwand für Sprachaufnahmen ruhig zu bekommen ist. Daran arbeite ich noch. Aber was bis dahin mit den Beiträgen, die in den nächsten Wochen abgeliefert werden müssen? Eine richtige Sprecherkabine möchte ich nicht, und sie wäre teuer und aufwändig.
Es hat mich interessiert, wie sich meine fünf Mikros so schlagen, wenn sie in gleicher Aufnahmesituation, mit gleichem Text, an den Start gehen. Ich wollte einfach wissen, welches mein Favorit ist. Am Ende war es wie vorher klar.

Manchmal liest man in technisch orientierten Fachzeitschriften einen Artikel, und man blättert nach wenigen Zeilen weiter. Technische Details ohne Ende, aufgelistet und aufgereiht, aneinander geklebt und gespickt mit Fachbegriffen. Manche kennt man als Fachmann, aber es gibt auch Autoren, die es schaffen, sogar den Fachmann zu verwirren. Ist man selbst Autor von Fachartikeln, könnte man sich fragen, was denn einen Beitrag lesenswert macht. Oder noch einen Schritt weiter: wann liest man einen Beitrag gerne und zu Ende? Ohne über Kollegen herfallen zu wollen, vielen Autoren scheint das eher egal zu sein, als ginge es nur darum, die notwendigen Textlängen inklusive Leerzeichen abzuliefern. Dabei sollte doch auch der Fachautor ein Interesse haben, dass seine Artikel gelesen werden. Was zur Frage führt, wann ein Beitrag lesenswert wird, angenommen wird, Spaß macht. Auch wenn der Spaß im beruflichen Umfeld nicht unbedingt erste Priorität hat.
Natürlich kommen als erste Maßnahme die altbekannten Regeln zum Einsatz. Möglichst farbige Verben, keine Substantivierungen, kein Amtsdeutsch, kurze und lange Sätze wechseln sich ab. Hamburger Verständlichkeitsmodell, logische Verläufe des Texts. Wie der Mathematiker sagt, ist das notwendig, aber nicht hinreichend. Auf der Suche nach Modellen, die "gute" Texte, auch im technischen Umfeld erlauben, fiel mir wieder dieses Heftchen in die Hände. Aus der Zeit auf der Journalistenschule. Über die Königsklasse des Journalismus, über das Feature.
 Es war 1987, als ich meine erste Email-Adresse bekam, sie war nur im Büro verfügbar, und auch nur über einen bestimmten Rechner. Das war eine Targon /35. Sie lautete boettchers.pad@nixdorf.com und hatte auch nur im Umfeld meines Jobs einen Sinn. Nämlich sich mit Kunden und Kollegen weltweit auszutauschen. In dieser Zeit eine Email-Adresse zu haben, machte mich zu einem Mitglied in einem erlauchten Kreis. Es gab keine Milliarden von Email-Adressen damals, vielleicht einige Hundertausende. Auch alle anderen Teilnehmer in diesem frühen Internet waren Ingenieure, Wissenschaftler, vielleicht noch einige Journalisten oder Lehrende. Kommuniziert wurde über Emails oder die Newsgroups. Letztere kennt heute fast niemand mehr, bis zum World Wide Web sollte es noch gut zehn Jahre dauern. Und noch länger bis zum Geschäftsmodell Facebook, das ich nicht mehr länger unterstützen wollte. Nicht wegen Zuckerberg, sondern aus anderen Gründen.
Es war 1987, als ich meine erste Email-Adresse bekam, sie war nur im Büro verfügbar, und auch nur über einen bestimmten Rechner. Das war eine Targon /35. Sie lautete boettchers.pad@nixdorf.com und hatte auch nur im Umfeld meines Jobs einen Sinn. Nämlich sich mit Kunden und Kollegen weltweit auszutauschen. In dieser Zeit eine Email-Adresse zu haben, machte mich zu einem Mitglied in einem erlauchten Kreis. Es gab keine Milliarden von Email-Adressen damals, vielleicht einige Hundertausende. Auch alle anderen Teilnehmer in diesem frühen Internet waren Ingenieure, Wissenschaftler, vielleicht noch einige Journalisten oder Lehrende. Kommuniziert wurde über Emails oder die Newsgroups. Letztere kennt heute fast niemand mehr, bis zum World Wide Web sollte es noch gut zehn Jahre dauern. Und noch länger bis zum Geschäftsmodell Facebook, das ich nicht mehr länger unterstützen wollte. Nicht wegen Zuckerberg, sondern aus anderen Gründen.
 Ich hatte in meiner seligen Jugend mal eine Freundin, die war gelernte Stenotypistin. Ein Beruf, der heute ausgestorben ist. Auf jeden Fall konnte sie auf der (elektrischen) Schreibmaschine so schnell schreiben wie ich zügig sprach. Das fand ich schon damals beeindruckend. Nun habe ich im Moment Mengen an Text zu produzieren, für einige Sendungen und Wortbeiträge. Nun bin ich ja allgemein vor nix fies, schon gar nicht vor dem technischen Fortschritt. Auch wenn ich niemals beim Radfahren das Smartphone in der Hand haben muss wie die Mädchen auf ihren uncoolen Hollandrädern, die wir damals nicht mal mit der Zange angepackt hätten. Geschweige denn gefahren. Was lag mit Windows 10 dann näher, als die eingebaute Spracherkennung Cortana zu nutzen und so die Texte schneller zu schreiben als mit meiner Vierfinger-Tippmethode? Versuch macht kluch.
Ich hatte in meiner seligen Jugend mal eine Freundin, die war gelernte Stenotypistin. Ein Beruf, der heute ausgestorben ist. Auf jeden Fall konnte sie auf der (elektrischen) Schreibmaschine so schnell schreiben wie ich zügig sprach. Das fand ich schon damals beeindruckend. Nun habe ich im Moment Mengen an Text zu produzieren, für einige Sendungen und Wortbeiträge. Nun bin ich ja allgemein vor nix fies, schon gar nicht vor dem technischen Fortschritt. Auch wenn ich niemals beim Radfahren das Smartphone in der Hand haben muss wie die Mädchen auf ihren uncoolen Hollandrädern, die wir damals nicht mal mit der Zange angepackt hätten. Geschweige denn gefahren. Was lag mit Windows 10 dann näher, als die eingebaute Spracherkennung Cortana zu nutzen und so die Texte schneller zu schreiben als mit meiner Vierfinger-Tippmethode? Versuch macht kluch.
 Meine ersten Seiten im Web habe so um 1995 online gebracht, zu einer Zeit, als man HTML noch mit einem normalen Texteditor schrieb. Und als CSS und JavaScript noch lange nicht erfunden waren. Später wechselte ich zu PlainEdit, der auch nicht viel mehr als ein Text-Editor war. Dagegen war dann Macromedia Dreamweaver Anfang des 21. Jahrhunderts geradezu Hochtechnologie. Es folgten etwas später die CMS-Systeme Typo3 und einige proprietäre Produkte, meine letzten Sites habe ich mit Joomla angelegt. Berufsbedingt kam nun auch WordPress ins Spiel. Diese meine aktuelle Site folgt den Entscheidungen des Unternehmens, für das ich arbeite. Mit allen Systemen, von Dreamweaver bis WordPress, habe ich inzwischen ausgesprochen "fette" Projekte hinter mir, deshalb an dieser Stelle meine Erfahrungen mit WordPress als CMS und einige wenige Seitenblick dazu zu Joomla.
Meine ersten Seiten im Web habe so um 1995 online gebracht, zu einer Zeit, als man HTML noch mit einem normalen Texteditor schrieb. Und als CSS und JavaScript noch lange nicht erfunden waren. Später wechselte ich zu PlainEdit, der auch nicht viel mehr als ein Text-Editor war. Dagegen war dann Macromedia Dreamweaver Anfang des 21. Jahrhunderts geradezu Hochtechnologie. Es folgten etwas später die CMS-Systeme Typo3 und einige proprietäre Produkte, meine letzten Sites habe ich mit Joomla angelegt. Berufsbedingt kam nun auch WordPress ins Spiel. Diese meine aktuelle Site folgt den Entscheidungen des Unternehmens, für das ich arbeite. Mit allen Systemen, von Dreamweaver bis WordPress, habe ich inzwischen ausgesprochen "fette" Projekte hinter mir, deshalb an dieser Stelle meine Erfahrungen mit WordPress als CMS und einige wenige Seitenblick dazu zu Joomla.

micscreen
Normalerweise habe ich in Niedersachsen mein Kellerstudio, perfekt gedämmt, den PC am anderen Ende des Raumes mit Absorbern akustisch abgetrennt, nur Monitor und Maus auf dem Aufnahmetisch. Gelegentlich möchte ich gerne auch in meiner Behausung in Ostwestfalen kurze Texte einsprechen, manchmal nur wenige Minuten lang. Doch selbst das Schlafzimmer mit Bett und Wandbehang ist zu hallig, wenn auch ruhig. Was tun? In solchen Fällen kann ein Micscreen wie von Thomann helfen. Hier fängt das Angebot bei knapp unter 50 Euros an, nach oben hin fast offen. Für mich wesentlicher war, dass ich bei nur gelegentlicher Nutzung den Micscreen auch verstauen muss. Und jedes Mal erst in den Keller zu laufen, macht die Sache nicht einfacher. Das muss doch anders, billiger und einfacher gehen. Tut es auch.
Man nehme:
- Zwei Platten Dämmschaumstoff, billig und mit viel Auswahl beim Pyramidenkönig; Pyramiden dämpfen besser, Noppen sind flacher; ich habe 7 cm-Pyramiden genommen.
- Zwei Hartschaumplatten 50 x 50 cm aus dem Baumarkt, alternativ auch Sperrholz (schwerer, aber stabiler). Weißer Hartschaum und weißer Schaumstoff sehen besser aus. Sonst das Sperrholz mit Spühfarbe bearbeiten.
- Zwei kleine Möbelscharniere.
- Klebstoff, klassisches Pattex für Platten und Scharniere, oder Sekundenkleber bzw. alternativ Senkkopfschrauben und Muttern für die Scharniere.
Die beiden Platten mit den Scharnieren verbinden, dabei bei den Scharnieren darauf achten, dass die Platten nach hinten ganz zusammen geklappt werden können. Den Schaumstoff auf der Vorderseite der Platten aufkleben, an der Verbindungsseite etwas Abstand lassen. Geht, weil die Schaumstoffplatten nicht ganz 50 cm lang sind. Fertig. Materialaufwand unter 15 Euros, Arbeitszeit eine Viertelstunde. Leicht angewinkelt stehen die Platten auf jedem Tisch. Unbenutzt verschwindet der Billig-Micscreen unter dem Bett oder im Schrank. Zwar kann man mit solchen Mitteln kein Badezimmer in eine Sprecherkabine verwandeln, aber für den Aufwand sind die Ergebnisse ganz brauchbar. Man bekommt den eigentlichen Hall nicht heraus, jedoch werden die hohen Frequenzanteile im Hall reduziert. Vielleicht ordere ich doch mal einen größeren Schirm bei Thomann und vergleiche die Ergebnisse.
Schlafzimmerstudio - ohne Micscreen
Schlafzimmerstudio - mit Micscreen

Steinberg UR22
Man hat nicht oft die Gelegenheit, zwei vergleichbare Produkte im echten AB-Test unter die Lupe nehmen zu können. Manchmal aber doch, denn nach einem USB-Audiointerface von Focusrite habe ich mir noch eins von Steinberg zugelegt, weil ich keine Lust zum ständigen Umbauen hatte. Ich hätte auch gleich ein zweites Focusrite nehmen können, doch die Neugier war zu groß. Einfach kann jeder. Um es vorweg zu nehmen, steht das Steinberg im Keller in der Aufnahme, das Focusrite oben im Arbeitszimmer an der Abmischstation. Weil sich eben heraus stellte, dass die Produkte zwar funktional sehr ähnlich sind, aber doch ihre Stärken und Schwächen haben. Nein, Schwächen haben beide nicht. Nur die Stärken sind unterschiedlich.
Im Focusrite werkelt eigene Hardware von Focusrite. Im Steinberg ist Yamaha-Hardware verbaut, was man spätestens bei der Treiberinstallation sieht. Beide Treiber laufen ohne Probleme, die angeblich instabilen Treiber von Steinberg sind mir nicht untergekommen. Nach der Installation jeweils von CD liefen die Interfaces ohne Murren. Nur auf der Focusrite-CD war ein alter Treiber, doch auf der Website gibt es neue Versionen.

Scarlett 2i2 USB
Technische Details spare ich mir, die finden sich für Focusrite und Steinberg zuhauf im Netz. Gemeinsam sind UR22 und 2i2 zwei symmetrische Eingänge für Mikrofone oder Line-Signale über eine Kombibuchse, ein 6,3 mm-Kopfhörerausgang und zwei symmetrische Ausgänge für Monitore über 6,3 mm-Klinke. Nur das UR22 hat noch zusätzlich ein MIDI-Interface und für einen der Eingangskanöle einen Hi-Z-Eingang für E-Instrumente. Allerdings mit Grenzen, denn der Eingangswiderstand ist mit 500 kOhm nicht wirklich hochohmig. Für mich irrelevant, denn ich produziere nur Sprache. Wird nur ein Eingang genutzt, wird mono auf beide Stereokanäle geroutet. Nutzt man beide Eingänge, wird konventionell auf die beiden Stereo-Kanäle geroutet. Monitor und Kopfhörer sind beim 2i2 getrennt regelbar. Beim UR22 gibt es einen Blend-Regler, dazu gleich mehr.
Kleiner Tipp am Rande. Hat man noch einen Behringer-USB-Treiber für deren Mischpulte installiert, ist in der Aufnahme auf dem PC ein unregelmäßiges Ticken zu hören. Bei beiden Interfaces, 2i2 wie UR22. Ist also Schuld des Behringer-Treibers. Hat mich etwas Suchen gekostet, weil ich erst WLAN oder ACPI im Verdacht hatte. Behringer-Treiber deinstalliert und es ist Ruhe.
Bedienung
Der große Regler für den Monitorausgang ist beim 2i2 als Audioausgang hilfreich, man kann schnell mal den Pegel herunter drehen. Dafür ist der Regler für den Kopfhörer etwas klein geraten. Für die Wiedergabe hat das 2i2 damit einen Vorteil. Dafür ist die Frontplatte des UR22 insgesamt aufgeräumter, aber wieder nicht so markant zu bedienen. Auch die Aussteuerung der Eingänge fällt beim 2i2 durch die dreistufige Anzeige rund um den Pegelsteller (grün/gelb/rot) leichter, das UR22 hat nur eine einzelne rote LED für die Übersteuerung. Steinberg hat sich für das Routing eine Art Balanceregler ausgedacht, der zwischen Eingang und PC, als DAW bezeichnet, überblendet. Nette Idee, in der Praxis aber wenig hilfreich. Das 2i2 hat für das Routing einen Schalter, ob man den Input auf dem Monitor haben will. Man sieht hier schneller, warum man hier oder dort nichts hört. Ansonsten haben beide Interfaces ein schweres Metallgehäuse mit Gummifüßen, da rutscht nichts und die beiden stehen satt und fest auf dem Tisch. Alle Buchen schön fest verschraubt, beim UR22 prangt ein dickes Neutrik auf den Kombibuchsen, die beim 2i2 funktionieren genau so gut. Der Kopfhörerregler beim 2i2 könnte etwas stabiler sein. Wirklich wackelig ist er nicht.
Im Punkt Bedienung würde ich dem 2i2 wegen des großen Monitor-Reglers, der intuitiveren Benutzung und der besseren Aussteuerungsanzeige den Vorzug geben. Ganz knapp.
Aufnahme
Bei beiden Geräten werden die Vorverstärker generell gelobt. In der Tat arbeiten auch beide für 139 Euro Preis ausgesprochen rauscharm. Bei dynamischen Mikros kommen beide an Grenzen und liefern den relativ größten Rauschpegel. Bei Kondensator-Mikros dagegen bleibt es sehr still, mit einem Rode NT1A und selbst dem billigen Thomann-Stäbchen ist keinerlei Rauschen zu hören. Mit dynamischen Mikros löst mein FetHead das Problem, das Rauschen ist dann absolut akzeptabel, nicht einmal das Gating-Plugin spricht an. Und wir sind hier auf der kompletten Preamp-Seite immer noch bei unter 200 Euro, nicht bei 2000.
Bei den Vorverstärkern liegen UR22 und 2i2 gleichauf. Das Rauschen des 2i2 klingt etwas dunkler als beim UR22, was manchmal weniger aufdringlich sein kann. Wirklich hörbar wird es nur mit dynmischen Mikros, und bei Sprachaufnahmen mit niedrigen Pegeln und deutlichen Pausen. Die Aufnahmen sind detailliert, luftig und klingen frei. Selbst die feinsten Details eines Großmembraners sind genaustens mitgenommen. Das geht in diesem Preisbereich kaum besser. Ein Patt.
Wiedergabe
Tatsächlich ist da ein Unterschied zwischen 2i2 und UR22. Das UR22 klingt sehr analytisch, mit ausgesprochen kristallinen Höhen. Zeichnet dadurch auch jedes noch so kleine Detail zwischen die Monitore. Das 2i2 klingt dagegen weicher und musikalischer, zeichnet auch sehr detailliert, aber nicht mit dieser etwas aufdringlichen Präsenz. Bei Sprache treten die Unterschiede nicht so deutlich hervor wie bei Musik. Bei längerem Hören von Musik jedoch fand ich das UR22 anstrengend.
Gemeinsam ist den beiden wieder die absolute Abwesenheit von Rauschen (Monitoring war direkt über eine Alesis-Endstufe und KRK R6-Monitore). Über Kopfhörer war dieser Klangunterschied nicht ganz so deutlich, aber immer noch wahrnehmbar (AKG K240 Studio). Noch ein Wermutstropfen am Rande: der Ausgangspegel des 2i2 für den Kopfhörer könnte ein Schüppchen mehr Pegel gebrauchen. Für mich reicht es, wer Live-Aufnahmen in der Kneipe aufzeichnet, kann für das 2i2 einen zusätzlichen KH-Verstärker gut gebrauchen. Da ich mehr Cmoy47-Verstärker als notwendig habe, kein Thema.
Fazit
Für unter 150 Euro sehr gute Preamps, vergleichbare Funktionalität, viel Metall und das 2i2 in der Bedienung einen Tucken angenehmer bei der Abhöre. Trotzdem war das UR22 kein Fehlkauf, beide Interfaces leisten für diesen Preis erstaunliche Dinge. Der Test hat für eine praktische und gute Arbeitsteilung gesorgt. Das UR22 kommt beim Einsprechen zum Einsatz, weil die Aufnahmen beider Interfaces kaum zu unterscheiden sind. Das 2i2 ist für das Produzieren zuständig, weil es weniger angestrengt und ausgeglichener klingt. Und weil man den großen Monitor-Regler schneller im Zugriff hat. Das UR22 wurde einmal im Studio eingepegelt, danach wird es nicht mehr angefasst und die weniger klare Bedienstruktur stört nicht mehr.
Alle kritisierten Punkte sind Meckern auf hohem Niveau. Beide USB-Interfaces arbeiten klaglos und für diese Preiszone mit erstaunlich guten Ergebnissen. Ich frage mich nur, wo die Entwicklung der Technik noch hin geht. In ein paar Jahren bekommt man wohl Audiointerfaces von heute zu 2000 Euro für 100.
Der Vorteil von Telefon-Interviews ist offensichtlich: keine Reisen, sie werden quasi automatisch kürzer und kompakter als das Gespräch am Kamin. Um solche Interviews mitzuschneiden, verwenden die Großen, also professionelle Sender, ziemlich teures und aufwändiges Equipment. Was sich in der Klangqualität solcher Interviews auch bemerkbar macht. Für den Hausgebrauch und den Gelegenheits-Interviewer keine Geschichte. Das muss etwas billiger gehen, geht es auch.
Hat man noch ein gutes altes schnurgebundenes Telefon, sind tatsächlich einfache Hardware-Lösungen zu kaufen. Ein Adapter wird zwischen Telefon und Hörer geschaltet, ein Klinkenstecker liefert das abgegriffene Gespräch an einen beliebigen Recorder. Nachteil: die Stimme des präsenten Interviewers ist nicht besonders klangvoll, denn das Mikro ist ja nun das des Telefons. Und wer hat noch ein schnurgebundenes Telefon? Also eine andere Lösung.
Diese hier kommt mit überschaubarem Aufwand an Hardware aus, wobei einige Komponenten meistens schon vorhanden sind. Oder für eine eher kleine Mark anzuschaffen.
- Ein Recorder. In diesem Falle ein Zoom H2n, bereits an Bord.
- Ein Kopfhörer, hier ein AKG K230 oder K240. Ebenso vorhanden.
- Ein Mikro. Das muss kein Highend-Teil sein, ein einfaches Kondensator-Mikro von Thomann reicht.
- Ein Mischpult. Das Behringer Xenyx 302 USB ist eines der kleinsten und billigsten. Gleich mehrfach vorhanden, bei mir.
- Ein PC (ach ...?)
- Eine sogenanntes Softphone, mit dem man über den PC und das Internet telefonieren kann.
Die Verbindung der einzelnen Komponenten ist nicht kompliziert.
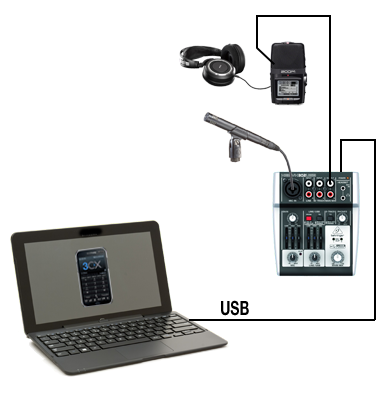
Interview-Hardware
Das Behringer-Pültchen hat den Vorteil, dass es direkt vom PC über USB stromversorgt ist und auch mit fast allen Softphones funktioniert. Andere Pulte, wie ein Xenys 1204 USB, wurden vom Softphone nicht als Mikro-Eingang akzeptiert. Und das 302 kann auch Kondensator-Mikros mit Phantomspeisung versorgen, ohne externes Netzteil. Eh man das Gebastel anfängt, sind die 49 Euro Investition sinnvoll.
Für die Konfiguration des Softphones sollte man die Hilfetexte in Anspruch nehmen. Kandidaten sind 3CX Phone oder NinjaLite. Wer seinen Telefonanschluss von 1&1 hat, ist gut dran. Im Benutzerportal bei 1&1 gibt es ein kostenloses Softphone zum Herunterladen, das zwar optisch grauenvoll ist, aber gut funktioniert und dazu mit der eingegebenen Telefonnummer sich selbst konfiguriert. Absolut narrensicher. Wenn man nicht vergisst, im Kundenportal für seine benutzte Telefonnummer ein Passwort einzutragen. Ansonsten reicht zur Installation seine Telefonnummer und eben das gesetzte Passowort.
Ist das Softphone installiert, ist man so gut wie fertig. Für die obige Konfiguration noch ein paar Hinweise:
- Auf dem 302er-Pult die beiden mittleren Tasten über dem Line-In beide drücken. Die linke, damit der PC bzw. das Softphone im Main-Mix landet, die rechte, damit sich die Gegenseite nicht selbst hört. So landet das Softphone nur auf dem Kopfhörerausgang. Mit der Latenz der VoIP-Verbindung verlieren ungeübte Sprecher sonst mit dem Echo sofort die Sprechfähigkeit.
- Aus dem Kopfhörerausgang des Pultes geht es dann in den Recorder, dazu braucht man ein Miniklinke zu Miniklinke-Kabel.
- Da der Kopfhörer am Recorder hängt, hört man genau das, was dort ankommt.
- Die Lautstärkenverhältnisse zwischen Mikro und Telefon sind oft sehr ungleich. Daher drehe ich die Balance des Mikroeinganges, meiner Stimme, ganz auf den rechten Kanal. Das Telefon drehe ich komplett auf den linken Kanal. So kann ich später in der Bearbeitung beide Kanäle getrennt normalisieren und erst dann zusammen führen. Und ich höre meinen Gesprächspartner mit dem "richtigen" Ohr.
- Vor dem eigentlichen Interview ein paar Minuten zum richtigen Einstellen der Pegel vorsehen, aber das sollte man zum Vorstellen oder Einleiten eh machen. Die Telefonleitungen haben sehr unterschiedliche Pegel.
Die ganze Konfiguration ist eher einfach und nicht schwierig zu handhaben. Was einen nicht davon abhalten sollte, das Interview inhaltlich gut vorzubereiten.

Røde Procaster
Zuerst habe ich Moderationen über das Großmembran-Kondensatormikro Røde NT-1A eingesprochen. Das hat die Vorteile eines warmen, detailreichen Klanges, aber den Nachteil einer hohen Empfindlichkeit. So dass jedes noch so winzige Geräusch, sei es ein knarrender Schuh oder ein Magenbrummeln, sehr deutlich mitgenommen wird. Dann bin ich auf das Røde Procaster umgestiegen, das nun hat die Vorteile eines guten Klanges für Sprecher und einer geringeren Empfindlichkeit für Nebengeräusche. Der Nachteil des dynamischen Procasters ist, dass es bauartbedingt eine nur sehr niedrige Ausgangsspannung liefert. Wie alle dynamischen Mikros, von Bändchenmikros ganz zu schweigen. Alle Versuche, mehr Gain ohne deutliches Rauschen zu bekommen, scheiterten. Auch der ART Tube MP oder ein selbst gebauter Preamp mussten so weit aufgezogen werden, dass das Rauschen nicht mehr akzeptabel war. Einen Preamp im vierstelligen Euro-Bereich, mit geringem Eigenrauschen, wollte ich mir nicht leisten. Ein vor das Procaster geschalteter 1:4-Übertrager nicht billiger Herkunft zog zwar den Pegel in das Pult hoch, machte jedoch auch dem Klang den Garaus. Erst wollte ich damit leben, dann wieder das Procaster in die Musiker-Kleinanzeigen schicken, bis mir zufällig in einem Video in You Tube der Triton Audio FetHead über den Weg lief.

Triton Audio FetHead
Ein wenig habe ich das Video für einen Marketing-Hype gehalten, aber für unter 80 Euro kann man ja mal einen Fehler machen. Nach wenigen Tagen Lieferzeit ist der FetHead heute aus den Niederlanden angekommen, Bedankt, Erwin. Ab ins Studio, etwas feixend, dass die Kollegen von Triton Audio dann doch am Ende zu viel versprochen haben, ging der FetHead heute online. Er wird einfach zwischen Mikro und Pult geschaltet, es gibt keine Bedienungselemente, sieht aus wie ein zu lang geratener XLR-Stecker. Vollmetall, schwer, stabil, wohl zuverlässig. Stromversorgung geschieht über Phantom Power. Dafür soll er gut 20 dB Gain liefern, abhängig von der Eingangsimpedanz des Pultes. Und das tut er bestens. Ich habe es nicht beweisen können, aber es scheint so, dass das verbleibende Rauschen vom Mikro selbst kommt, denn ohne angestecktes Mikro kommt erst Rauschen vom Preamp im Pult bei hohem Gain. Der FetHead ist absolut still, verstärkt den Pegel des Procasters so weit, dass der Gain-Regler meines Behringer 1204 nicht einmal halb aufgezogen werden muss. Es ist nicht null Rauschen wie beim NT-1A, aber das bisschen Rauschen ist mehr als akzeptabel. Das Procaster darf bleiben. Nein, das Procaster wird ab jetzt das Standard-Mikro.
Als wenn es damit nicht genug wäre, verändert der FetHead zusätzlich im positiven Sinne den Klang des Mikros. Es klingt einen Tucken wärmer, definierter und voluminöser. Ich vermute, dass die höhere Eingangsimpedanz des FetHead - im Vergleich zum Pult - die Spule des Procasters weniger bedämpft und dadurch der Klang besser wird. Mehr Gain, mehr Sound, und das für unter 80 Euro. Eines der wenigen Beispiele, dass ein Produkt nicht nur hält, was versprochen wird, sondern im Grunde mit seiner Rauscharmut viel teurere Preamps degradiert.
Neben der Standardversion gibt es noch den FetHead BC (für Broadcast) für harte Umgebungsbedingungen, der in die Mikroleitung eingeschleift wird, einen konstanten Gain hat und den man wohl mit einem Panzer überfahren darf. Dann ist da noch eine Variante, die die Phantomspeisung durchschleift, das macht der FetHead nicht und schützt so das dynamische Mikro. Noch eine andere Version nimmt als Eingang einen 6,3 mm-Klinkenstecker auf und ermöglicht den Anschluss von E-Instrumenten an ein Pult ohne Höhenverluste. Nette kleine Helferlein, die in dieser Firma zu finden sind.
Dann drücke ich dem noch recht jungen Unternehmen in unserem Nachbarland alle verfügbaren Daumen. Der FetHead ist ein Produkt, das den Preamp-Markt so aufmischen könnte wie damals Behringer den Mischpult-Markt. Hohe Qualität zu einem unglaublich niedrigem Preis.
Nachtrag: ich habe heute mal mein gutes altes SM57 über den FetHead angeschlossen. Kaum zu glauben, wie gut ein solches Standard-Mikro klingen kann. Wenn man ausreichend Abstand zum Mikro behält, wegen des Nahbesprechungseffektes, kann sogar ein SM57 verdammt gut klingen.

HTML-Mail
Nachdem nun ein Mail-Template verfügbar ist, das die meisten Mail-Clients einigermaßen verstehen, muss das auch verschickt werden können. Tatsächlich gibt es einige Möglichkeiten. Ein paar seien vorgestellt.
Thunderbird
Privat würde ich Thunderbird immer vorziehen, denn entweder kann ich das HTML-Template im Editor mit Ctrl-A/Ctrl-C kopieren und den HTML-Code direkt in Thunderbird mit Ctrl-V einfügen, weil Thunderbird die direkte Eingabe von HTML erlaubt. Die komfortablere Version ist das Add-On Stationary für Thunderbird. Mit diesem Tool kann ich die irgendwo auf der Platte liegende HTML-Datei direkt als Vorlage benutzen, zusammen mit den üblichen Möglichkeiten von Thunderbird wie Verteilerlisten und so weiter. Und ich kann mir im Prinzip beliebig viele Vorlagen anlegen, die auch beliebig in einem Verzeichnis liegen können, nicht in einem einzelnen und auch noch geschütztem Verzeichnis wie bei Outlook. Dann kann ich auch wieder mit Dreamweaver editieren, denn die Vorlagen sind online, werden sie verändert, übernimmt sie Thunderbird ohne weitere Aktionen. Im Gegensatz zu Outlook, ist das Template geändert, verwendet Stationary bei den nächsten Mail die neue Vorlage.
Outlook
Nun musste der Newsletter aber mit Outlook verschickt werden, weil nur dort die korrekte Absenderadresse verwendet werden konnte, und auch die riesigen Verteiler zu finden waren. Um in Outlook HTML-Mail aus eigener Produktion zu verschicken, wäre die naheliegendste Methode das Anlegen eines eigenen Stationaries, einer Briefvorlage. Nicht grundsätzlich schwierig. Die Datei mit dem Mail-Template bekommt die Endung .htm statt .html und wird (hier für Outlook 2007 und Windows 7) in C:\Program Files\Common Files\microsoft shared\Stationary abgelegt. Nach einem Neustart von Outlook ist das Template als Vorlage über Extras | Optionen | E-Mail-Format | Briefpapier und Schriftarten ... | Design als Vorlage zu finden. Hat man auch als Nachrichtenformat HTML statt Rich-Text in diesem Dialog gewählt, taucht das Template tatsächlich beim Anlegen einer neuen Mail auf.
Ein Vorteil oder auch Nachteil, je nach Gusto, ist es, dass die Mail nun auch in Outlook bearbeitet werden muss. Oder man erstellt die Mail komplett in Dreamweaver (oder im Editor seiner Wahl) und kopiert diese dann jeweils wieder in den Stationary-Ordner. Das war mir erstens erstens etwas kryptisch, zweitens wolle ich gerne wegen der besseren Kontrolle den Newsletter in Dreamweaver erstellen. Und weil meine Website die Skriptsprache PHP erlaubt, bin ich einen etwas anderen Weg gegangen.
Der Newsletter wird komplett in Dreamweaver erstellt. Ist er fertig, gehe ich in den Code, kopiere ihn mit Ctrl-A und Ctrl-C ins Clipboard. Nun habe ich ein einfaches Formular (Quellcode hier)und ein kleines Skript in PHP, welches nichts weiter macht als den HTML-Code an den gewählten Empfänger verschickt, hier mein Outlook-Konto. Aus Outlook kann ich dann über Forward den Newsletter an die entsprechenden Verteiler verschicken.
Das wirkt jetzt etwas umständlich, tatsächlich erleichert es die Arbeit, weil das Editieren in Dreamweaver viel komfortabler ist als in Outlook. Wenn ich zum Beispiel merke, dass mir eine CSS-Formattierung fehlt oder sie nicht passt, kann ich in Dreamweaver mal eben anpassen, in Outlook müsste ich erst die Vorlage editieren, Outlook neu starten und warten. Daher bin ich mit dem HTML-Editor viel flexibler und schneller. Das Rüberschicken und Weiterleiten sind dann nur noch Sekunden, die beim Editieren lange eingespart wurden.
Dann nur PHP
Wenn man schon über PHP sowieso Mail verschicken kann, ist das auch erweiterbar. So kann der Newsletter nun auch komplett von dort in die Welt geschickt werden. Die Nutzung von PHP bietet weitere Optionen, zum Beispiel können die Adressen und Namen einer Datenbank entnommen werden. Setze ich im Template Tokens wie [VORNAME] oder [DATUM], kann ich durch eine einfache String-Ersetzung einfach das Token durch den tatsächlichen Namen des Adressaten ersetzen und so den Newsletter personalisieren.
Basiert meine Website auf Typo3, gibt es Plugins, die nicht nur das Versenden eines Newsletters übernehmen, sondern über die sich User auch für den Newsletter an- und abmelden können.
Welchen Weg man nun wählt, hängt vom Geschmack und den technischen Möglichkeiten ab. Sicher ist es über Outlook gerade dann einfach, wenn das Template einmal erstellt wird und dann von technisch eher Ungeübten mit Inhalt gefüllt. Denn dann muss ich nur Outlook vermitteln. Bin ich aber technisch versiert und der Sprache PHP mächtig, kann ich mir sehr komfortable Oberflächen und Tools bauen.
Your mileage may vary ...
HTML-Mail
Schon seit langer Zeit können Mail-Programme mit HTML umgehen. Damit ist es möglich, Mails nicht nur als reinen Text, sondern auch wie die eigene Web-Seite gestaltet zu versenden. Der Vorteil: der Look&Feel der Mail kann an das Design der Site angepasst werden, es entsteht ein Wiedererkennungswert, eine durchgehende Identität, heute Corporate Identity genannt. Wenn dann Newsletter verschickt werden, so wie bei Lidl oder beim Otto-Versand, wechselt das Bild beim Anclicken von Links in die eigene Site nicht, es bleibt ein konsistentes Eindruck im Design, was für ein professionelles Auftreten nicht unerheblich ist.
Die meisten Mail-Programme erlauben schon lange das Verfassen von Mail mit Formattierung in HTML, allerdings ohne direkte Gestaltungsmöglichkeiten, sie verpacken lediglich den Text in einem HTML-Rahmen. Um "richtige" HTML-Mails zu erzeugen, kommen entsprechende Tools wie Adobe Dreamweaver zum Einsatz, es wird in der eigenen WebSite eine Seite gestaltet, die dann als Vorlage für die zu versendenden Mails dient. Eventuelle Bilder müssen in der Site liegen, Links müssen eine vollständige URL haben, damit sie beim Empfänger auch erreichbar sind. Hat man es geschafft, diese Mail zu verschicken, könnte kurze Zeit später von jemandem die Frage kommen, warum man ihm so ein kryptisches Zeugs geschickt hat. In der Regel nutzt dieser Jemand MS Outlook, und man fragt sich, warum das denn jetzt nicht funktioniert hat.
In diesem ersten Artikel also ein Rahmen, wie man solche HTML-Mails erzeugt und wie sie dann auch von Outlook-Nutzern gesehen wie gesendet ankommen. Um das tatsächliche Versenden geht es dann im zweiten Teil.
Aufbau des HTML-Codes
Die zu versendende Mail wird wie eine normale Seite aufbereitet, man sollte allerdings bei der Größengestaltung daran denken, dass eine Mail nicht immer an einem großen Monitor erscheint und daher die Mail schmaler gehalten werden sollte. Bilder etc. werden wie gewohnt eingebettet, müssen hier aber eine vollständige URL haben, sonst bekommt der Mail-Client auf der Empfängerseite diese Bilder nicht mit. Ansonsten bildet man das Design seiner Website möglichst genau nach, dort, wo dann als Webseite der Content steht, kommt später der Mail-Inhalt dazu. Für meine Site sähe das Mail-Template dann etwa so aus. Nicht vergessen sollte man direkt am Anfang, möglichst wenig formattiert, einen Link auf eine Online-Version der Mail, die dann in der eigenen Site steht.
Nun gibt es da ein paar Stolperfallen, die ich erst durch Puzzlelei heraus gefunden habe. Eine davon ist, dass viele Mail-Clients zwar das Nachladen von Bildern in Mails erlauben, aber nicht den Zugriff auf externe CSS-Dateien. Daher muss das komplette CSS bereits in der HTML-Datei mit eingebettet sein, ein externes CSS wird in der Regel ignoriert, und das nicht nur von Outlook. JavaScript ist nicht möglich, nur der Mail-Client Mozilla Thunderbird hat einen Firefox intern, der auch JavaScript ausführt.
Ein weiterer Trick ist, dass sowohl CSS- wie auch HTML-Formattierungen von Mail-Programmen sehr unterschiedlich interpretiert werden. Je weiter die Programme von Open Source entfernt sind, desto eigenwilliger diese Interpretation. Der Gipfel ist ...
Outlook
Als ich meinen ersten HTML-Newsletter fertig hatte, so in HTML und CSS codiert wie gewohnt, sah das Ergebnis in Thunderbird auch fast wie gewünscht aus. Sogar in Outlook 2003 waren nur geringe Abweichungen zu sehen. In Outlook 2007 allerdings kam nur Schrott an, die Mail war fast nicht mehr lesbar. Sie war nicht mehr lesbar. Warum? Lange musste ich nicht forschen.
Bis Outlook 2003 war Outlook innerlich zwiespältig. Das Erstellen von HTML-Mails erfolgte mit Komponenten von Winword, das Rendern - Umsetzen von HTML in Grafik - aber mit Komponenten des Internet Explorers. Daher war das, was man in Outlook 2003 schickte, schon nie das, was Outlook 2003 dann anzeigte. Um diese Diskrepanz zu beheben, machte Microsoft etwas, was mit dem Ausschneiden eines Loches in der Hose vergleichbar ist: ab Outlook 2007 werden HTML-Mails nicht nur mit Winword geschrieben, sondern auch empfangene Mails in HTML von Winword gerendert. Da die HTML-Fähigkeiten von Winword eher rudimentär sind, konnte Outlook 2007 mit meinen Divisions und umfangreichen CSS-Formattierungen gar nichts mehr anfangen. Und so sah das Ergebnis auch aus.
Abhilfe konnte also nur sein, lediglich soviel HTML und CSS zu verwenden, dass Winword es noch versteht. Wenigstens hilfreich dabei ist, dass Microsoft die HTML-Fähigkeiten von Winword in diesem und einem zweiten Dokument aufgelistet hat. So musste ich einen Schritt zurück machen, weg von modernem CSS und HTML und zurück zu Tabellen. Denn Tabellen sind das Einzige, was Winword halbwegs versteht.
Das Resultat
Dieses Mail-Template arbeitet nun wieder mit Tabellen, und mit etwas Mühe und Probieren ist es auch mit Tabellen möglich, einigermaßen ein Layout zu realisieren. Hier ist einmal der HTML-Quellcode, jedoch gibt es auch darin Workarounds. So kann Winword keine Images vernünftig formattieren, daher wird für den Rahmen um Bilder einmal CSS verwendet, für Outlook ist ein vspace="5" im Tag erforderlich.
Dieser HTML-Code ist nun für alle Mail-Clients einigermaßen kompatibel.
Fazit
Zuerst scheint es eher übersichtlich zu sein, HTML-Mails zu verschicken. Tatsächlich stolpert man von einem Problem zum anderen und hat rasch einige Stunden verbracht, bis auch Outlook die Mail in etwa so anzeigt wie gewünscht. Vielleicht gibt mein Beispiel etwas Hilfe.
Im zweiten Teil geht es dann darum, wie man nun die HTML-Seite als Mail vor die Tür bekommt, denn direkte Eingabe von HTML erlaubt praktisch kein Mail-Client. Außer Thunderbird.
Es soll Zeiten gegeben haben, so um Ernest Hemingway herum, da hat man sich einfach mit einer Schreibmaschine und einigen Blättern Papier hingesetzt und hat geschrieben. Erst viel später wurde das Tippex erfunden, eine Erlösung für den Seltenschreiber. Kurz nach der Erfindung des Faxgerätes kamen PCs und damit Word und Multiplan, endlich konnte man schreiben, wieder laden und sich verschreiben, konnte speichern und wieder editieren. Ja, ich sprach gerade von den seligen Zeiten mit MS-DOS und rein textlichen Oberflächen.
Programme, mit denen man nur schreibt und trotzdem die wichtigsten Parameter im Blick hat, nämlich Anzahl Zeichen mit Leerzeichen und ohne, Zeilen, Wörter, es gibt sie wieder. Programme, bei denen nichts ablenkt, wo die Konzentration nur auf dem Schreiben liegt. Drei davon seien hier vorgestellt, die ersten beiden im Grunde sehr ähnlich, das dritte ausgefeilter und trotzdem nicht verschwiegen, weil Tools wie Notepad in der Bedienung überlegen.

Q10
Q10 (http://www.baara.com/q10/) ist ein Fullscreen-Editor, der in seinem Schriftbild den Wünschen des Nutzers weitgehend angepasst werden kann. Es gibt keine Menues oder Icons, in der Info-Leiste werden die wichtigen Eigenschaften des Textes angezeigt. Die nicht wenigen Funktionen des Editors sind über Funktionstasten erreichbar. Die Tippgeräusche einer Schreibmaschine können eingeblendet werden, auch Papier- und Textfarben sind einstellbar. Sollte man die Funktionstasten vergessen haben, reicht die Taste F1 und man bekommt eine Übersicht.

WriteMonkey
WriteMonkey (http://writemonkey.com/) ist Q10 ähnlich, aber in viel weiteren Grenzen einstellbar und mit mehr Funktionen gesegnet. Das Prinzip ist das gleiche wie in Q10, es gibt nur noch einen Bildschirm ohne Kommando-Icons, Funktionen, Buttons oder Menus. Nur ein Blatt und die Schrift darauf. Auch WriteMonkey zeigt die Zahl der Buchstaben, Wörter und Zeilen an, zusätzlich können Seitensteuerungen leicht eingegeben werden, wie z. B. ein +++ für den Seitenwechsel oder >> und >>> für Einrückungen.

Notepad++
Wer es nicht ganz so radikal reduziert haben möchte, kann auf Notepad++ (http://notepad-plus-plus.org/) zurück greifen. Im Gegensatz zu Q10 und WM ist Notepad++ ein vollständiger Texteditor, der ursprünglich für das Edititieren von Quelltexten für Programmierer gedacht war, sich aber zum reinen Texterfassen prima eignet. So werden als Beispiel selektierte Wörter zusätzlich im gesamten Text hervor gehoben, so dass dann Häufungen von Wörtern schnell sichtbar sind.
Schön an allen drei Tools ist, dass sie Freeware und damit kostenlos zu haben sind. Alle drei zeigen die gesamte oder selektierte Zeichenzahl, Zeilen oder Absätze an, sind in Farben und Schriftarten anpassbar. Bei mir hat sich übrigens MS Consolas als Schriftart gut bewährt, ist in Windows 7 vorinstalliert und ansonsten in der Microsoft-Site kostenlos zu bekommen.